Mysql概述
基本描述
Mysql是典型的关系型数据库(RDBMS),按照行来存储。
sql语句
- DDL(Data Definition Language),数据库定义语句,常见的有CREATE TABLE、TRUNCATE TABLE、DROP等
- DML(Data Manipulcation Language),数据操作语句,常见的有INSERT、UPDATE、DELETE
- DQL(Data Query Language),数据查询语句,常见有SELECT
架构图
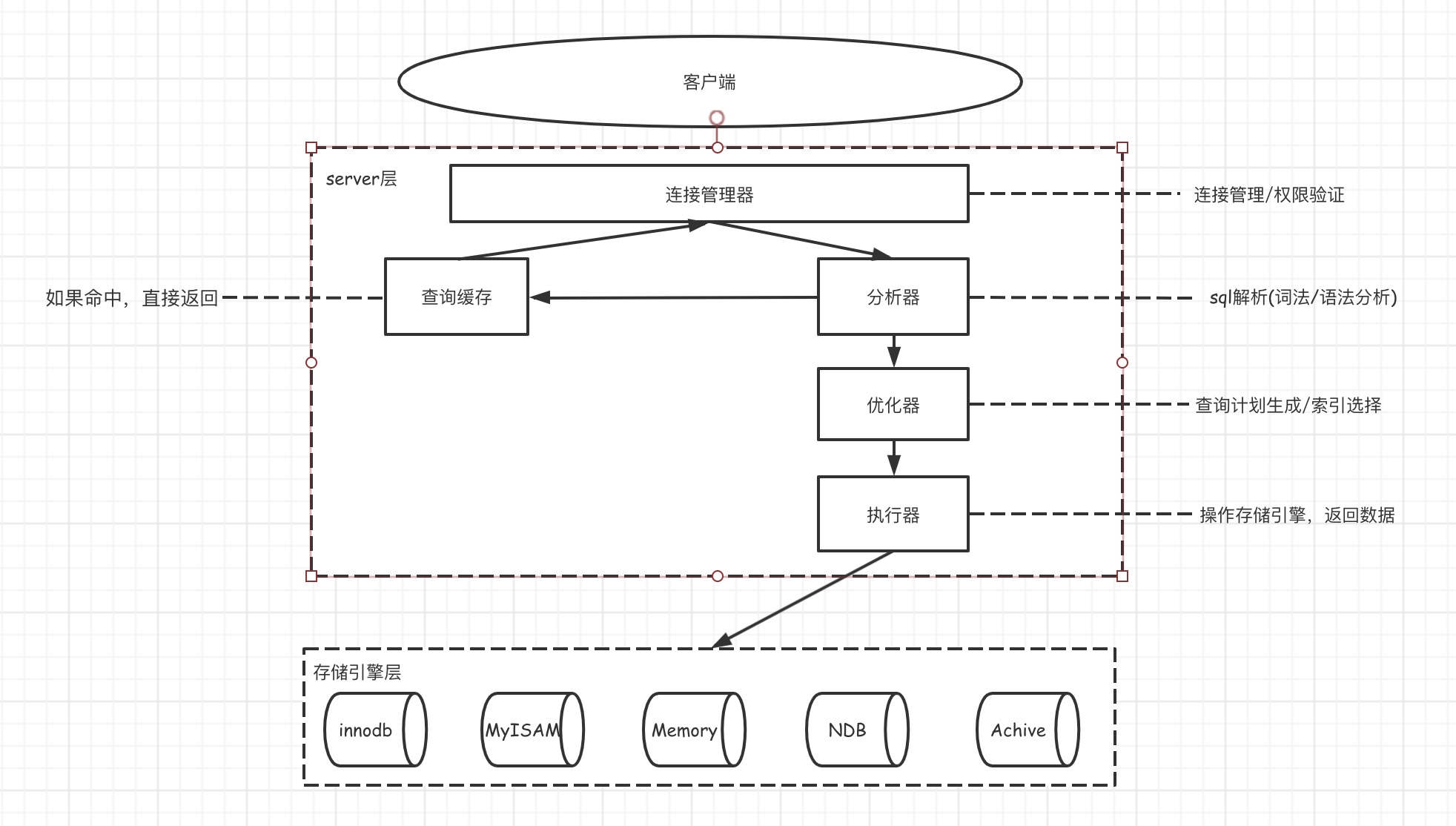
如图所示,Mysql整体上分为server层和存储引擎层,其中引擎层被设计为可插拔的插件的形式。因此,Mysql支持多种存储引擎,比较常见的有Innodb和MyISAM。默认的的引擎是Innodb。存储引擎层提供数据操作的接口,供server层调用。Mysql的server层包含连接器(Connector)、解析器(Parser)、优化器(Optimizer)、执行器(Executor)以及查询缓存。
- 连接器:负责和客户端的连接管理,以及权限认证等。连接器会直接和查询缓存、解析器连接。
- 查询缓存:sql语句和查询结果的映射,如果命中,则直接返回
- 解析器:对sql语句进行词法、语法分析
- 优化器:根据数据库的索引信息、统计信息生成查询计划,以及计划要使用的索引等
- 执行器:调用数据库下的存储引擎执行sql计划,并返回结果
注意:查询缓存一般在生产环境是关闭的,因为查询缓存需要完全匹配,并且相关的表中数据有任何变化时会失效。因此,当数据频繁变化时,一方面缓存容易失效,另外,增加不必要的开销。 存储引擎层的逻辑是:获取复合条件的第一条,然后再一次获取第二条,以此类推。
Mysql查询语句的执行顺序
一条典型的mysql查询语句如下: SELECT xxx FROM T1 JOIN T2 ON T1.id=T2.tid WHERE xxx GROUP BY xxx HAVING xxx ORDER BY xxx LIMIT xxx 其执行按照如下顺序:
FROM 确定要查询的表,如果有JOIN,则根据关联的字段生成表笛卡尔积的临时表TEMP1
WHERE 根据条件过滤,过滤掉不合法的记录,生成TEMP2
GROUP BY根据分组字段,进行分组,并执行相关的聚合函数,生成TEMP3
HAVING 根据分组后的条件进行过滤,生成TEMP4
SELECT 选出需要的字段,生成TEMP5
DISTINCT 过滤重复的数据,生产TEMP6
ORDER BY根据相应字段进行排序,返回一个游标
LIMIT 翻页,返回数据
注意:ON既可以进行过滤,也可以执行添加,在于使用的是inner join还是outer join。ON的过滤是在WHERE之前。 WHERE和HAVING作用的时间点不同,WHERE是作用在原始表的列上的,HAVING是在聚合后的。所以HAVING能够使用聚合后的列,也能够使用别名。WHERE只能看见原有表中的别,不能使用别名。但是,HAVING对于SELECT语句中没有的列是不能使用的,WHERE可以,只要原始表中存在。
Mysql执行计划
当我们使用explain查看mysql生成的执行计划时,会返回针对该条sql语句的预估的一些信息,其中包括:
id
id表 示的是mysql的执行优先级。由于一条sql中可能包含多个字查询,所以可能会有多条记录。id越大,优先级越高,id相同,则按照顺序依次执行。
select_type
- SIMPLE 不包含字查询的简单查询
- PRIMARY 包含字查询的语句中的主查询,即最外面的查询
- SUBQUERY/MATERIALIZED 包含子查询中的子查询,包括SELECT和WHERE后的子查询,MATERIALIZED则是WHERE中IN后面的子查询
- DERIVED 包含子查询,FROM后的子查询
- UNION 包含UNION操作的后面的表
- UNION RESULT 包含UNION查询的合并结果
type
执行计划中的type,这是个比较重要的参考,可能的值有all > index > range > ref > eq_ref > const > system。开销由大到小。
- all 需要全表扫描
- index 需要扫描索引
- range 需要三秒索引的一段
- ref 非唯一索引的相等查询或者IN查询
- eq_ref 主键索引、或者非空唯一索引的相等查询或者IN查询
- const 主键查询,常量连接
- system 查询系统表的一些信息
possible keys/key
可能使用的索引/最终决定使用的索引,如果对执行计划的索引的key的不满意,则可以使用USING INDEX去建议引擎使用,但是最终不一定使用。也可以使用FORCE INDEX去让引擎强制使用某个索引。
rows
语句要扫描的记录行数,这是个估计值。这是根据mysql统计数据和是否使用索引估计的一个值。
extra
其他附加信息,可能会有的值
- using filesort 使用外部排序对结果进行排序,通常含有order by
- using index select的列可以在索引中直接拿到,即覆盖索引
- using index condition 使用联合索引时,可以在取出索引时,执行过滤,即把这部操作从server层下推到了存储引擎层
- using where 查询的列上没有建索引,或者区分度不高时,需要在server层进行过滤
- using temporary 使用临时表,一般在多表join,group by时会有
存储引擎对比
一般我们常用就只有MyISAM(Indexed Sequential Access Method)和InnoDB两种存储引擎。
- MyISAM: 支持表锁,不支持事务,不支持外键,维护了一个表的所有行数的数据,因此查询总行数会很快一般适用于OLAP型的应用
- InnoDB:支持行锁、表锁,支持事务,支持外键,由于使用了MVCC,所以查询总行数,需要计算。一般适合于OLTP和OLAP型应用。